
El procesamiento del lenguaje natural (PLN) se está convirtiendo en una de las tecnologías más transformadoras de la actualidad. Esta rama de la inteligencia artificial tiene el potencial de cambiar la forma en que interactuamos con la tecnología, al permitir que las máquinas comprendan y generen lenguaje humano de manera más precisa. Desde los asistentes virtuales hasta los sistemas avanzados de traducción automática, el PLN está moldeando el futuro de la interacción entre humanos y máquinas.
El Natural Language Processing (NLP) o procesamiento del lenguaje natural, PLN, es la tecnología que permite a las máquinas entender, interpretar y generar lenguaje humano. En otras palabras, se trata de la capacidad de una computadora para procesar y comprender el lenguaje hablado o escrito, similar a cómo lo hacemos nosotros los humanos.
Historia del PLN
El PLN no es un campo nuevo. Sus raíces se remontan a los primeros esfuerzos en lingüística computacional en la década de 1950, cuando los investigadores intentaban construir sistemas capaces de comprender y generar lenguaje natural. En ese momento, la idea de que las máquinas pudieran interpretar el lenguaje humano era revolucionaria. Sin embargo, estos primeros sistemas eran primitivos, basados principalmente en reglas gramaticales simples.
Fue con el desarrollo del aprendizaje automático y, más recientemente, las redes neuronales profundas, que el PLN experimentó un salto cuántico en su evolución. Estas nuevas técnicas han permitido a las máquinas aprender patrones del lenguaje a partir de grandes volúmenes de datos, lo que ha llevado a una mayor precisión y capacidades en los sistemas actuales de PLN.

La historia del Procesamiento del Lenguaje Natural (PLN) está marcada por una evolución constante, desde los primeros enfoques basados en reglas hasta los avances modernos con modelos de aprendizaje profundo. A continuación, exploramos las principales etapas históricas que han marcado el desarrollo del PLN.
1. Inicios: Los Primeros Modelos Basados en Reglas (1950-1970)
Los primeros esfuerzos en el PLN surgieron en la década de 1950, principalmente como una extensión de la lingüística computacional y el campo emergente de la inteligencia artificial (IA). En esta época, los investigadores se centraron en construir sistemas que pudieran procesar lenguaje humano mediante reglas gramaticales y lógicas predefinidas.
Uno de los hitos más importantes de esta época fue el desarrollo del Test de Turing en 1950 por el pionero británico de la computación, Alan Turing. El Test de Turing no era una técnica específica de PLN, pero proponía un desafío clave para el campo: si una máquina podía mantener una conversación en lenguaje natural de manera indistinguible de un ser humano, entonces se podría considerar «inteligente».
2. Primeros Intentos de Traducción Automática (1950-1960)
El interés por la traducción automática creció rápidamente durante la Guerra Fría. En 1954, se llevó a cabo el famoso experimento Georgetown-IBM, uno de los primeros sistemas de traducción automática, que intentó traducir un conjunto limitado de oraciones del ruso al inglés.
Aunque este sistema demostró cierto potencial, estaba basado en reglas simples y podía traducir solo frases sencillas. Su éxito inicial generó expectativas desproporcionadas, lo que condujo al «invierno de la IA» a finales de los años 60, cuando los avances en PLN y otras áreas de la inteligencia artificial fueron más lentos de lo esperado.
3. Surgimiento de los Enfoques Estadísticos (1970-1990)
En la década de 1970, la comunidad de investigación comenzó a explorar enfoques estadísticos y probabilísticos para el procesamiento del lenguaje. Esta transición fue un cambio importante, ya que se pasó de las reglas estrictas y predefinidas a los modelos basados en datos.
Un avance crucial en este período fue la introducción de los modelos ocultos de Markov (HMM), utilizados en el reconocimiento de voz y el etiquetado de parte del discurso (PoS Tagging). Estos modelos probabilísticos permitían a las máquinas aprender patrones del lenguaje a partir de datos, lo que mejoró considerablemente su capacidad para manejar la variabilidad y ambigüedad inherente al lenguaje natural.
4. La Explosión de los Corpora y el Aprendizaje Automático (1990-2010)
Con el crecimiento exponencial de los datos textuales disponibles en línea, como el contenido en la web y las bases de datos digitales, los investigadores comenzaron a aplicar técnicas de aprendizaje automático de manera más amplia. La disponibilidad de grandes conjuntos de datos textuales, llamados corpora, facilitó la construcción de modelos más sofisticados de procesamiento del lenguaje.
A finales de los años 90 y principios de los 2000, el enfoque de PLN se desplazó hacia los modelos estadísticos. En lugar de escribir reglas para cada idioma o tarea, los sistemas de PLN ahora utilizaban grandes cantidades de datos etiquetados para entrenar modelos. Uno de los grandes avances de esta época fue el éxito de los modelos de traducción automática basados en frases, que superaban a los enfoques basados en reglas.
El Proyecto WordNet, lanzado en 1985 y ampliado en los años 90, también jugó un papel crucial. WordNet es una base de datos léxica del inglés que agrupa palabras en conjuntos de sinónimos (sinsets) y mapea relaciones semánticas entre ellas. Este recurso fue clave para muchas tareas de PLN, como la desambiguación semántica.
5. El Auge de las Redes Neuronales y los Modelos de Lenguaje (2010-presente)
El verdadero cambio de paradigma en el PLN moderno llegó con la popularización de las redes neuronales y los modelos de aprendizaje profundo en la década de 2010. Las redes neuronales profundas, en particular las redes neuronales recurrentes (RNN) y las redes neuronales convolucionales (CNN), demostraron ser excepcionalmente efectivas en tareas relacionadas con el lenguaje.
Sin embargo, fue la introducción del modelo Transformer en el artículo “Attention is All You Need” de 2017, lo que marcó un antes y un después en el PLN. El Transformer superó a las arquitecturas anteriores al permitir que los modelos de lenguaje se entrenaran de manera más eficiente y manejaran grandes secuencias de texto. Esto llevó al desarrollo de modelos de lenguaje preentrenados como:
- GPT (Generative Pre-trained Transformer) de OpenAI: Lanzado en varias versiones (GPT, GPT-2, GPT-3, y ahora GPT-4), este modelo se entrenó en enormes cantidades de datos de Internet, permitiendo generar texto coherente y realizar una variedad de tareas de PLN.
- BERT (Bidirectional Encoder Representations from Transformers) Introducido en 2018, BERT permitió una mejor comprensión del contexto en ambas direcciones (izquierda y derecha) dentro de una oración, mejorando considerablemente el rendimiento en tareas de comprensión de texto.
Estos modelos preentrenados utilizan un proceso de «preentrenamiento» en grandes cantidades de datos textuales, seguido de una «afinación» en tareas específicas. Esto les permite generalizar bien a diferentes tipos de tareas de PLN sin necesidad de ser entrenados desde cero para cada una.
6. La Nueva Generación de Modelos Multimodales y Multilingües (2020 en adelante)
En los últimos años, los avances en PLN no solo se han centrado en mejorar la calidad de la comprensión y generación del lenguaje, sino también en expandir el alcance de los modelos a entornos multimodales (texto, imágenes, video, audio) y multilingües. Modelos como DALL-E, que genera imágenes a partir de texto, y CLIP, que combina imágenes y texto, son ejemplos de esta tendencia.
Además, los modelos como mT5 (Multilingual T5) y XLM-R (Cross-lingual Language Model) son capaces de manejar múltiples idiomas simultáneamente, lo que mejora el procesamiento de lenguas menos representadas y permite una mejor traducción y comprensión en diferentes contextos culturales.
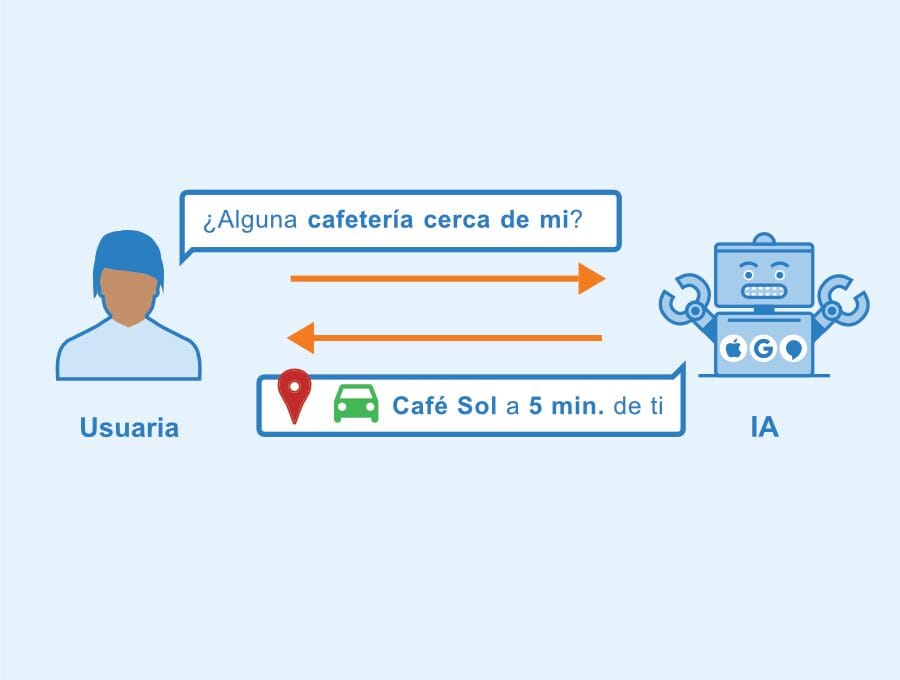
¿Cómo Funciona el Procesamiento del Lenguaje Natural?
El PLN es una disciplina compleja que involucra múltiples niveles de análisis lingüístico, desde el preprocesamiento de datos hasta el uso de algoritmos avanzados para comprender el significado de un texto o una conversación. A continuación, describimos los pasos clave del funcionamiento del PLN:
1. Preprocesamiento de Datos
El primer paso en cualquier sistema de PLN es el preprocesamiento de datos. Este proceso prepara el texto o el habla para que la máquina pueda interpretarlo. Algunas de las técnicas más comunes incluyen:
- Tokenización: Dividir el texto en unidades más pequeñas, como palabras o frases. Esto permite que el sistema trabaje con piezas individuales de información.
- Normalización: El proceso de convertir las palabras a una forma estándar, por ejemplo, transformando todas las palabras a minúsculas.
- Eliminación de palabras vacías: Se eliminan palabras comunes y sin mucho valor semántico (como «y», «o», «pero») para que el algoritmo se concentre en términos más importantes.
- Lematización: Reducción de las palabras a su forma base. Por ejemplo, «corriendo» se convierte en «correr», lo que permite una interpretación más coherente.
- Etiquetado de parte del discurso (PoS Tagging): Asignar a cada palabra una categoría gramatical (sustantivo, verbo, adjetivo, etc.).
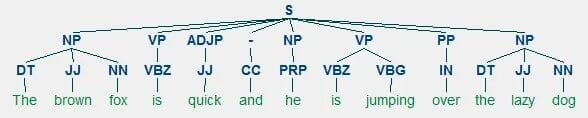
2. Análisis Sintáctico
Una vez que el texto ha sido preprocesado, el sistema realiza un análisis sintáctico, lo que implica entender la estructura gramatical del lenguaje. Esta etapa permite que el sistema comprenda cómo las palabras se relacionan entre sí dentro de una oración. Algunas de las técnicas más comunes en este análisis son:
- Análisis de dependencia: Se identifica la relación entre las palabras en una oración, por ejemplo, qué palabra es el sujeto y cuál es el verbo.
- Árboles sintácticos: Representan gráficamente la estructura gramatical de una oración.
3. Análisis Semántico
El siguiente paso en el PLN es el análisis semántico, que tiene como objetivo entender el significado del texto. Mientras que el análisis sintáctico se centra en la estructura, la semántica se preocupa por lo que realmente significan las palabras y oraciones. Esto incluye:
- Desambiguación léxica: Determinar el significado correcto de una palabra con múltiples significados basándose en su contexto. Por ejemplo, la palabra «banco» puede referirse a una institución financiera o a un asiento, dependiendo del contexto en el que se use.
- Reconocimiento de entidades nombradas (NER): Identificación de nombres de personas, lugares, fechas y otras entidades específicas.
- Resolución de correferencias: Determinar a qué entidad se refiere un pronombre en una oración. Por ejemplo, en la oración «María vio a Juan y le dio un libro», el sistema debe identificar que «le» se refiere a Juan.
4. Modelos Basados en Aprendizaje Automático
Una de las grandes innovaciones en el PLN moderno es el uso de modelos basados en aprendizaje automático, especialmente aquellos que emplean redes neuronales profundas. Estos modelos no requieren reglas predefinidas, sino que aprenden a partir de grandes cantidades de datos textuales.
Modelos de Lenguaje Preentrenados
Los modelos de lenguaje preentrenados, como GPT-4 o BERT, han revolucionado el PLN. Estos modelos son entrenados en grandes conjuntos de datos textuales y pueden generar o comprender texto con una alta precisión. Utilizan un tipo de red neuronal llamada transformador, que es extremadamente eficaz en el manejo de secuencias de texto y en el modelado del contexto de las palabras.
5. Generación de Lenguaje Natural
El último paso en muchos sistemas de PLN es la generación de lenguaje natural (NLG), que permite que las máquinas no solo comprendan el texto, sino que también lo generen. Esta tecnología se utiliza en asistentes virtuales, sistemas de resumen automático y otras aplicaciones que requieren que las máquinas produzcan respuestas o textos coherentes.
Texto no estructurado vs Texto Estructurado
El proceso de PLN comienza con lo que se llama texto no estructurado. El texto no estructurado es básicamente el lenguaje tal como lo usamos cotidianamente. Por ejemplo, si dices: «Agrega huevos y leche a mi lista de compras», esa oración es clara para nosotros, pero para una computadora es simplemente un conjunto de palabras sin formato.
Para que una computadora pueda entender este tipo de comandos, necesita convertir ese texto no estructurado en datos estructurados. Un ejemplo de esto sería organizar la frase anterior en una lista con elementos como «huevos» y «leche», que la máquina pueda procesar.
| Texto No Estructurado | Datos Estructurados |
|---|---|
| «Agrega huevos y leche a mi lista de compras» | Elemento de lista: Huevos, Elemento de lista: Leche |
Componentes del PLN: NLU y NLG
El NLP o PLN tiene dos funciones principales:
- Natural Language Understanding (NLU), que se encarga de convertir texto no estructurado en datos estructurados.
- Natural Language Generation (NLG), que realiza el proceso inverso, generando texto no estructurado a partir de datos estructurados.
| Proceso | Descripción |
|---|---|
| Natural Language Understanding (NLU) | Convierte texto no estructurado en datos estructurados. |
| Natural Language Generation (NLG) | Genera texto no estructurado a partir de datos estructurados. |
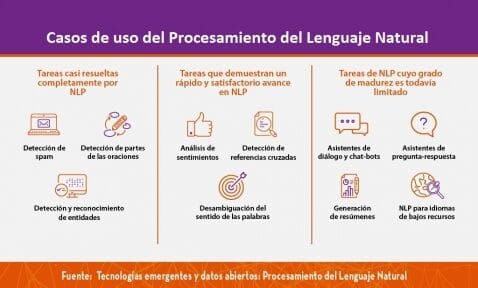
Aplicaciones del NLP
- Traducción Automática: El procesamiento del lenguaje natural es clave en las herramientas de traducción. No solo se trata de traducir palabra por palabra, sino de comprender el contexto de las frases.
- Asistentes Virtuales y Chatbots: Los asistentes virtuales como Siri o Alexa utilizan NLP para procesar comandos verbales, mientras que los chatbots analizan texto escrito y toman decisiones basadas en ese análisis.
- Análisis de Sentimientos: El PLN puede analizar reseñas de productos o correos electrónicos para determinar si el tono es positivo o negativo, o incluso si es sarcástico.
- Detección de Spam: Mediante el análisis de patrones como el uso excesivo de ciertas palabras o errores gramaticales, el PLN puede identificar si un correo electrónico es spam.
| Aplicación | Descripción |
|---|---|
| Traducción Automática | Entender el contexto de una frase para traducir adecuadamente de un idioma a otro. |
| Asistentes Virtuales/Chatbots | Interpretar comandos verbales o textuales y tomar acciones basadas en ellos. |
| Análisis de Sentimientos | Identificar la emoción o tono de un texto, ya sea positivo, negativo o sarcástico. |
| Detección de Spam | Identificar si un mensaje es spam basándose en patrones de lenguaje y comportamiento. |
Procesos Clave en el PLN
- Tokenización: Dividir un texto en pequeñas unidades llamadas tokens (palabras individuales o conjuntos de palabras).
- Stemming y Lemmatización: Reducir las palabras a su forma base o raíz. Por ejemplo, la palabra «correr» se reduciría a «correr» en el proceso de stemming, mientras que en lemmatización, «mejor» se reduciría a «bueno».
- Etiquetado de Partes del Discurso (POS Tagging): Determinar el papel que juega cada palabra en una oración, por ejemplo, si es un verbo o un sustantivo.
- Reconocimiento de Entidades Nombradas (NER): Identificar nombres propios en un texto, como personas, lugares o empresas.
| Proceso | Descripción |
|---|---|
| Tokenización | Dividir un texto en tokens individuales para su análisis. |
| Stemming y Lemmatización | Reducir las palabras a su forma base o raíz para normalizar su significado. |
| Etiquetado de Partes del Discurso (POS) | Identificar el rol gramatical de cada palabra en una oración. |
| Reconocimiento de Entidades Nombradas (NER) | Detectar nombres propios en un texto, como personas o lugares. |
Conclusión
La evolución del Procesamiento del Lenguaje Natural refleja un camino desde enfoques basados en reglas y gramáticas formales hacia sistemas modernos impulsados por enormes cantidades de datos y redes neuronales profundas. Desde los primeros intentos rudimentarios de traducción automática hasta los modelos de lenguaje avanzados como GPT-4 y BERT, el campo del PLN ha recorrido un largo camino en las últimas décadas, permitiendo que las máquinas no solo comprendan, sino también generen lenguaje humano de manera cada vez más natural y eficiente.
Con los avances en modelos multimodales y plurilingües, el PLN sigue avanzando hacia una comprensión más completa y rica del lenguaje humano, lo que abrirá nuevas posibilidades para la interacción entre humanos y máquinas.
El PLN es una herramienta fundamental en el campo de la inteligencia artificial que permite a las máquinas procesar y entender el lenguaje humano. Gracias a una serie de técnicas como la tokenización, el etiquetado de partes del discurso, el PLN facilita desde la traducción automática hasta la detección de spam. A medida que avanzamos en el desarrollo de la inteligencia artificial, el papel del PLN seguirá siendo crucial para mejorar la interacción entre humanos y máquinas.
¿Te gustaría profundizar más en este fascinante tema? No dudes en explorar los enlaces que he dejado en el articulo o en dejar tus preguntas en los comentarios. ¡Gracias por leer!

- ¿Deberíamos establecer límites al desarrollo de la inteligencia artificial? - diciembre 19, 2024
- ¿Cómo la entrada automatizada de datos transforma su negocio? - diciembre 18, 2024
- Los 10 indispensables recursos para clases en línea. - diciembre 17, 2024